3Q 2023 | IN-7033
Registered users can unlock up to five pieces of premium content each month.
Changing Landscape of (Telco) Networking |
NEWS |
In the 1990s, hardware networking was the order of the day. Around 2003, IEEE standardized the protocol used today for virtual Local Area Networks (LANs). In the same year, we saw the first release of the Xen hypervisor. However, networking logic was still delegated to the underlying hardware element by connecting Virtual Machines (VMs) to the physical network with Layer 2 bridges. In 2009, we saw the first Open vSwitch release. The introduction of Open vSwitch marked the start of the network virtualisation era, the genesis of Software-Defined Networking (SDN). At this point, networking logic shifted from hardware to software. In 2010, we witnessed the first OpenStack summit. Going further, in 2012, Docker emerged. Docker focused primarily on packaging applications with container images. At this point, container networking was still built on OpenStack technology. In 2014, there was the first GitHub commit for Kubernetes (K8s), today widely viewed as the cloud Operating System (OS).
K8s introduced a new approach to service handling, observability, and networking. For example, there was no concept of a network or a subnet in K8s. In principle, that unlocked innovation. In practice, K8s continues to rely on iptables, the most widely available networking stack/program to configure IP packet filter rules. Iptables predates K8s, and its underlying design is not a good match for cloud-native workloads. Why not? Because existing kernel building blocks (processing unit, memory handling, namespaces) are inflexible. They lack K8s Pod (a group of containers) awareness and cannot be tied to higher-layer service abstractions. Beyond that, they only allow for global policies, as opposed to per-container and/or per-service policies. The solution? Cilium, an open-source Container Network Interface (CNI) and extended Berkeley Packet Filter (eBPF). eBPF is a core component of Cilium. It offers a fundamental design shift for future mobile networks where it matters most: host kernel layer and user space layer.
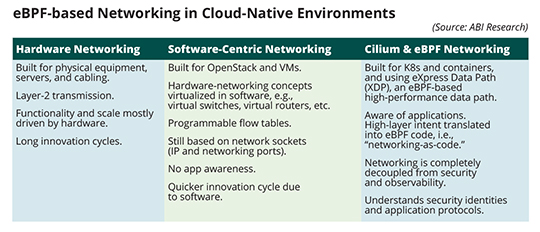
Cilium & eBPF's Fundamental Design Shift |
IMPACT |
eBPF can be viewed as a general-purpose execution engine. It enables dynamic programming of the Linux (or MS Windows) kernel space, a layer that has unrestricted access to underlying host resources, such as the Central Processing Unit (CPU), memory, etc. Bordering the kernel space, there is the user space, a layer where “normal” user processes and apps run. The function of the former is to prevent apps running in the latter from interfering with each other and from interfering with the host. eBPF allows kernel behavior to be extended or observed at runtime without changing the kernel source code—and without reboot. eBPF consists of three pillars: 1) kernel space eBPF programs that respond to events; 2) user space programs that insert networking, security, and observability custom code into the kernel space; and 3) eBPF maps that facilitate information sharing between the kernel and user space. Cilium “fixes” iptables’ shortcomings by handling the load balancing of (network) services as follows:
- Run eBPF Programs in the Kernel Networking Stack: Here, Cilium handles North-South traffic. For example, the external network packet arrives at a host’s Network Interface Card (NIC). The packet goes through the networking stack in the kernel space. That includes steps like routing lookups and Network Address Translation (NAT), among others. Next, the packet goes through the networking stack in the Pod to reach the user space app or 5G Core (5GC) Container Network Functions (CNFs) hosted in the telco cloud. This is a convoluted process. eBPF optimizes the data path by simplifying the kernel’s networking stack. In fact, it bypasses it altogether to send the packet directly into the networking stack of the Pod in the user space. In other words, it achieves “in-node” high-performance load balancing by avoiding much of the overhead associated with iptables’ routing tables.
- Run eBPF Programs at the Socket Layer: Here, Cilium handles East-West traffic among Cilium managed network endpoints/nodes, or Pods in K8s environments. Cilium replaces netfilter IP rules with eBPF maps to transport data directly from inbound sockets at a local endpoint to outbound sockets. Essentially, this allows for efficient handling of East-West traffic by running eBPF programs in the NIC driver as close to the hardware as possible. There are no NAT and no routing lookups. There is no other overhead associated with iptables. This achieves “inter-node” high-performance, low-overhead load balancing.
Why do Communication Service Providers (CSPs) need eBPF? To answer that, CSPs need to consider the two available options to enhance kernel functionality: 1) make a change to the code base; and 2) use kernel modules that can be loaded/unloaded on demand. Both are tedious for many reasons. First, familiarity with the existing code is required. Second, Linux is a general-purpose OS. The community needs to accept a new patch before it becomes part of a new release. And finally, even when a new patch is accepted, it takes time for it to be available in a production environment. That is because different verticals, including the telco cloud, don’t use Linux directly. They use Linux distributions, such Canonical’s Ubuntu, VMware Photon OS, and Wind River Linux, that package the kernel with other components. The kernel’s sheer size compounds complexity. According to The Linux Foundation, the kernel consists of 69,000 files and 28 million lines of code. In that respect, eBPF enables magnitudes of enhancement in creating new building blocks required to dynamically program the kernel in a safe, performant, and scalable way.
eBPF's Applicability in Telco Networks |
RECOMMENDATIONS |
Today, Meta uses eBPF exclusively for Layer 4 load balancing at scale. Every packet that reaches Meta.com goes through eBPF. Cloudflare has also migrated away from netfilter components to eBPF. Beyond that, Cilium is the default CNI for Amazon Elastic Kubernetes Service (EKS), Google Cloud, and Microsoft Azure. In telcos, Bell applies eBPF in the network as an engine to replace iptables rules. Cilium remains a K8s CNI, so using K8s as a cloud OS is a prerequisite for wider eBPF adoption in telcos. Beyond that, telco networks carry traffic that is characterized by high-packet throughput. Consequently, a CSP’s K8 instance is likely to have a larger Maximum Transmission Unit (MTU) relative to a Meta’s or Cloudflare’s traffic. To address that challenge, CSPs should have an interconnect in place that supports large MTUs to minimize implementation challenges, particularly for Wide Area Network (WAN)-type use cases. For that, CSPs will look to eBPF vendors to guide them on how the technology can make their networks more efficient whilst mitigating associated challenges.
Second, eBPF provides additional observability for 5G CNFs. This is a welcome enhancement because built-in tracing for information exchange within microservices is a challenge, as noted in ABI Insight “Virtual Machines Are the Standard in Telco Cloud, But Containers Are the Future.” CSPs can use eBPF as a telemetry collector, event handler, and tracer for the kernel space, low-layer system events. That serves several purposes, namely enhancing security, and even estimating energy consumption for cloud-native apps. Moreover, CSPs can configure eBPF with Artificial Intelligence (AI)/Machine Learning (ML) algorithms and supplementary network data sources, such as Fault Management (FM) and Performance Management (PM) records for added observability context. However, mobile networks, in 5G and beyond, require automated service assurance and near real-time network and subscriber experience monitoring. At this point, eBPF does not perform complex correlation, analyses, and network incident management. Beyond that, eBPF’s observability support for user space is not as robust as that found in the kernel space.
Third, eBPF allows CSPs to redesign Network Functions (NFs). For example, to date, vendors support CSPs virtualize their NFs by porting existing code into x86 platform without optimizing it. Now, there are efforts to use eBPF to re-design NFs like UPF. That bodes well for promising use cases like IoT Gateways and edge local breakout. However, Telco NFs remain complex components of data transfer. How to fit that complexity into a small and packaged eBPF program remains to be seen. To conclude, eBPF can unlock a new market in Telco infrastructure software. But first, we need more proof points on how eBPF helps CSPs achieve their commercial objectives. Vendors with low-layer OS knowledge of the software stack (e.g., Red Hat, VMware and Wind River) must take the lead on that front. They should develop a deep understanding of CSPs’ competitive environment as the basis for further product innovation. Vendors that stand to win business will be those that develop eBPF products that don’t just serve CSPs network requirements, but also help them deal with the relentless, discontinuous change that software tools like eBPF create..